Xin chào tuần mới các anh em Mì AI, chúng ta đã làm việc với Computer Vision – thị giác máy tính rồi. Hôm nay chúng ta sẽ thử dạy cho máy tính sử dụng thính giác để nghe âm thanh qua bài toán dạy cho máy tính nghe và phân biệt âm thanh bằng CNN nhé.

Bài toán của chúng ta sẽ có dạng là khi chúng ta đưa một đoạn âm thanh (được lưu dưới file wav) cho máy tính nghe. Máy tinh sẽ có thể phân tích và trả về cho chúng ta kết quả âm thanh đó là gì, ví dụ: “tiếng chó sủa”, “tiếng còi xe”,…
Okie, let’s go!
Phần 1. Chuẩn bị nguyên vật liệu
Vẫn như mọi khi, các bạn tạo thư mục MiAI_Sound_Classifier để lưu các món của bài này. Sau khi tạo xong, các bạn chuyển vào thư mục đó và gõ lệnh:
git clone https://github.com/thangnch/MiAI_Sound_Classifier .
Sau khi đợi một chút, các bạn sẽ thấy 1 số folder và file được tải về. Các bạn chuyển vào thư mục data và tạo các thư mục theo cấu trúc như sau:
- Tạo thư mục train và test trong thư mục data.
- Tạo thư mục wav trong thư mục data
Tiếp theo, các bạn tải dữ liệu âm thanh để train và test tại đây. Sau khi tải xong, các bạn có file datawav.zip, giải nén ra các bạn có 2 thư mục train và test (khác với train và test các bạn tạo bên trên nhé), các bạn copy vào trong thư mục wav đã tạo ở trên nhé.
Sau khi đã tạo và tải xong dữ liệu, các bạn cài đặt các thư viện cần thiết bằng lệnh sau nhé:
pip install -r setup.txt
Chú ý, tại thời điểm các bạn triển khai, có thể một số thư viện đã nâng cấp và gây lỗi, các bạn chú ý nhé.
Phần 2. Tư tưởng thuật toán dạy máy tính nghe
Trước đến nay khi nhắc đến xử lý âm thanh, mọi người hay sử dụng kiến trúc RNN như LSTM bởi vì âm thanh là dữ liệu sequence. Tuy nhiên cũng có một cách là sử dụng CNN để xử lý được. Sở dĩ làm như vậy được vì chúng ta sẽ có một bước biến các âm thanh thành hình ảnh spectrogram của nó. Ví dụ như hình dưới
Như vậy, từ chỗ xử lý âm thanh, chúng ta quy về bài toán phân loại hình ảnh bằng CNN. Cụ thể bài này chúng ta sẽ làm các bước sau:
- Quá trình train:
- Bước 1. Chuyển hết toàn bộ dữ liệu wav sang file ảnh và lưu vào các thư mục train và test khác nhau.
- Bước 2. Đọc các ảnh trong thư mục train và thực hiện train model. Chú ý là nhãn đầu ra output sẽ ở trong file train.csv (cột class)
- Quá trình test:
- Bước 1. Chuyển âm thanh cần test về dạng file ảnh.
- Bước 2. Đưa file ảnh vào mạng để predict ra class tương ứng.
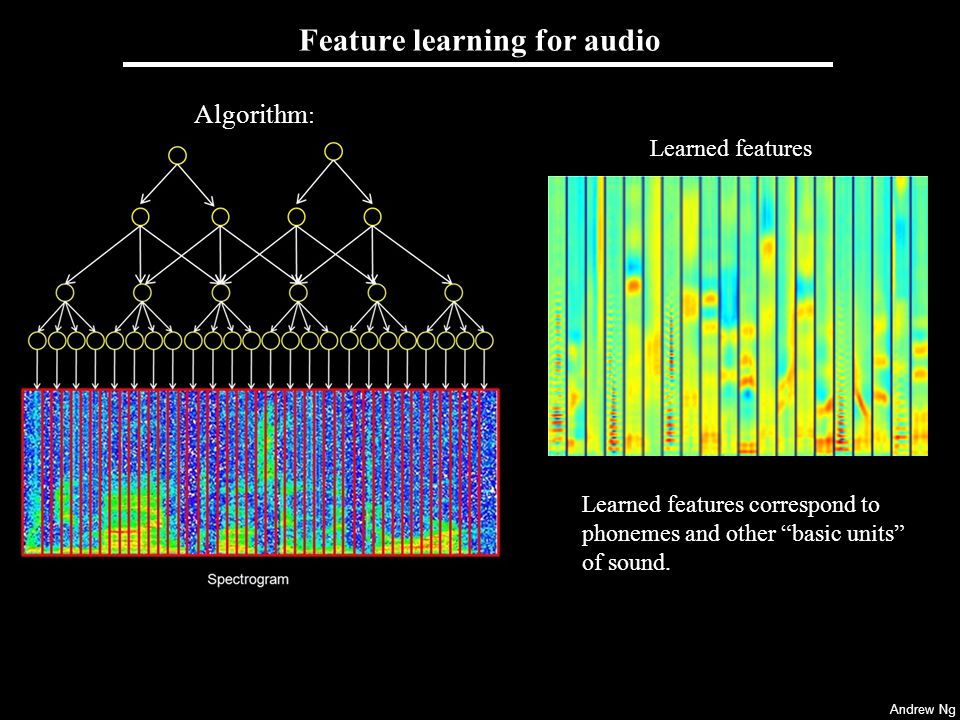
Phần 3. Mã nguồn chương trình
Bài này các bạn cần chú ý một số file gồm:
- File Preprocessing.py: File này mình tiền xử lý dữ liệu. Convert toàn bộ các file wav chứa trong thư mục data/wav/train và data/wav/test thành các file ảnh và lưu trong thư mục data/train va data/test
- File train_model.py: Thực hiện train model lưu file train vào file model.h5.
- File test_model.py: Thực hiện predict thử set test của chúng ta và hiện kết quả ra màn hình.
Mã nguồn dã được mình comment chi tiết từng dòng, các bạn đọc trong file để nắm được code nhé.
Phần 4. Thực hiện chương trình dạy máy tính nghe và phân loại âm thanh
Đầu tiên, các bạn chạy file Preprocessing.py để tiền xử lý dữ liệu. Chạy lệnh python như sau:
python preprocessing.py
Phần này chạy sẽ hơi lâu một chút, các bạn có thể để máy đó và làm việc khác hoặc chạy overnight cho đỡ sốt ruột. Haha!
Đợi một chút khi màn hình thông báo “Process done!” thì là xong nhé!Sau khi chạy xong, các bạn chú trong thư mục data/train và data/test sẽ có rất nhiều file spectrogram như sau:
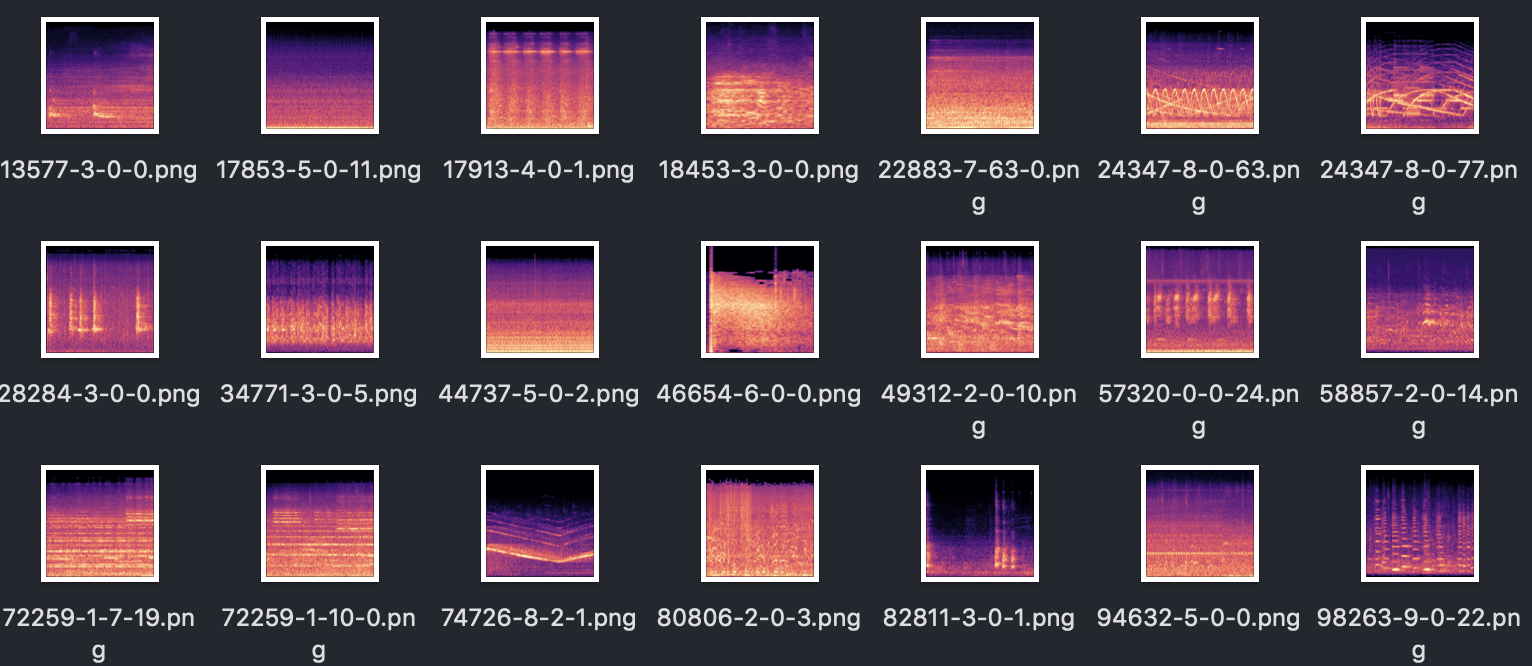
Tiếp theo chúng ta sẽ thực hiện train và test model bằng lệnh:
python train_model.py
Đợi cho model train xong và hiện lên màn hình chữ Model trained! là okie.
Bây giờ các bạn thử chạy file test model bằng lệnh:
python test_model.py
Đợi chút, predict xong các bạn sẽ thấy hiện lên màn hình các dòng chữ:
Prediction values= ['car_horn', 'dog_bark', 'car_horn', 'car_horn', 'car_horn', 'dog_bark', 'dog_bark', 'dog_bark', 'dog_bark', 'children_playing'] Real values= 0 car_horn 1 car_horn 2 car_horn 3 car_horn 4 car_horn 5 dog_bark 6 dog_bark 7 dog_bark 8 dog_bark 9 children_playing
Như vậy model đã dự đoán đúng class 9/10 các file âm thanh trong set test của chúng ta. Các bạn có thể thử với các file dữ liệu khác trong test set nhé.
Rồi, như vậy chúng ta đã xong bài toán dạy máy tính nghe và nhận diện âm thanh – thính giác máy tính. Rút ra từ bài này là nhiều khi từ các bài toán khó, chưa có cách giải quyết nhưng nếu như biết cách biển đổi và hiểu dữ liệu thì chúng ta có thể đưa về các bài toán thông thường -bài toán phân loại ảnh chó/mèo quen thuộc.
Chúc các bạn thành công. Nếu trong quá trình thực hiện có gì khó khăn, hoặc cần thảo luận, các bạn có thể post lên group để cùng trao đổi nhé Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup .
Hãy tham gia cùng cộng đồng Mì AI nhé:
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn
Youtube: http://bit.ly/miaiyoutube
Nguồn tham khảo: https://github.com/EXJUSTICE/Urban_Sound_Classification/blob/master/Sound%20Class%20with%20Spec%20Images%20Draft.ipynb