[NLP Series #4] Lảm nhảm cuối tuần về biểu diễn văn bản bằng trong học máy (2/2)
Chào anh em hôm nay chúng ta sẽ đi tiếp phần 2 của hạng mục biểu diễn văn bản trong học máy với phương pháp Word2Vec và vẫn đúng vào dịp cuối tuần 😀
Nếu bạn nào chưa đọc bài số 1 thì có thể đọc tại đây: [NLP Series #3] Lảm nhảm cuối tuần về biểu diễn văn bản bằng trong học máy (1/2).
Trong bài trước chúng ta đã tìm hiểu cách văn bản bằng BOW, One-hot, TDIDF, ma trận đồng xuất hiện… và hôm nay sẽ là Word2Vec nhé.
Mình lại xin nhắc lại lần nữa là bài này và tất cả các bài trên Mì AI đều viết dựa vào thực nghiệm với mục đích làm sao các bạn hiểu để sử dụng. Mình xin phép bỏ qua mọi thuật ngữ chuyên ngành khó hiểu. Nếu có cao thủ đi qua xin bỏ quá ah và cũng xin góp ý nếu bị hiểu sai.
Haha, trình bày đã xong bây giờ lên đường!
Phần 1 – Vì sao cần một phương pháp khác?
Câu hỏi đầu tiên chúng ta đặt ra là: “Đã có một mớ các phương pháp kia rồi sao không dùng mà còn nghĩ ra PP mới làm gì?”.
Câu trả lời chính vì các nhược điểm của các PP đó như: không gian biểu diễn lớn và tăng theo số từ vựng, không thể hiện được mối quan hệ giữa các từ….Và thế là phương pháp nhúng từ Word Embedding ra đời và từ đó nhiều bài toán xử lý ngôn ngữ tự nhiên (NLP) được giải quyết với độ chính xác cao hơn nhiều, chuẩn hơn nhiều so với trước.
Tóm váy phần 1: Cần PP mới vì cái cũ chưa tốt!
Phần 2 – Vậy Word2Vec là cái gì?
Ý tưởng chính của phương pháp này là thay vì chỉ đếm và lưu số lần cùng xuất hiện của hai từ nào đó thì bây giờ Word2Vec sẽ được train để học cách đoán ra word lân cận từ word hiện tại. Cách làm này giúp cho tính toán và lưu trữ nhanh hơn và khi thêm một từ mới vào vocabulary thì cũng thuận tiện hơn.
Các bạn chú ý nhé “learn” để đoán ra word lân cận từ word hiện tại. Từ đó nghĩa là :
- Word2Vec là deep learning và cụ thể là mạng NN
- Ta phải có quá trình train cho nó chứ không phải chỉ tính toán đơn thuần như các phương pháp trước.
Word2Vec sẽ biểu diễn mỗi từ bằng một vector với một số chiều N nào đó (ví dụ 300 chẳng hạn). Và nó được train, được tối ưu weights sao cho những từ càng “gần” nhau về mặt khoảng cách (khoảng cách giữa 2 vector từ) là các từ hay xuất hiện cùng nhau trong văn cảnh, các từ đồng nghĩa.
Tóm váy phần 2: PP mới tên là Word2Vec và nó biểu diễn mỗi từ bằng 1 vector.
Phần 3 – Thế Word2Vec nó hoạt động cụ thể như thế nào?
Trong phần 2, ta đã biết sau khi áp dụng cái W2V thì mỗi từ sẽ biểu diễn bởi một vector với số chiều bằng N nào đó. Vậy thì làm như nào sinh ra được 1 vector cho 1 từ, chả nhẽ sinh random? (WTH!!!)
Tất nhiên là không rồi và bây giờ chúng ta sẽ cùng nhau đi tìm hiểu cách sinh ra cái vector thần thánh đó nhé!
Đầu tiên là thuật toán của Word2Vec
Có 2 cách tiếp cận cái món Word2Vec này nhé, đó là:
- CBOW Model: Cho ngữ cảnh (các từ xunh quanh) và đoán ra xác xuất xuất hiện từ đích.
- Skip-gram Model: Cho từ hiện tại và đoán xác xuất của các từ ngữ cảnh (các từ xung quanh)
Các bạn có thể hiểu rõ hơn qua việc quan sát hình vẽ dưới đây:

Và dù dùng phương pháp nào trong 2 PP trên đi chăng nữa thì W2V cũng cần một mạng NN thông thường (ko phải CNN nhé, một số bạn hay dùng CNN nên dễ nhầm, mình phải nói rõ ra là vì thế). Và chúng ta sẽ đi train cái mạng này bằng dữ liệu ta có (là các từ trong corpus thôi chứ có gì khác đâu, bạn nào chưa hiểu corpus là gì đọc lại Phần 1 nha). Train xong thì có gì? Có weights, tất nhiên rồi và từ weights đó ta sẽ có vector đặc trưng biểu diễn cho từ, chính là thứ ta cần!
Ơ thế nhưng lại thắc mắc là train mạng xong thì moi ra cái vector đặc trưng dư lào?
Đây đây, có ngay câu trả lời cho các mem ngay! Ở đây chúng ta tìm hiểu tổng quan trước, chưa phân biệt PP CBOW hay Skip-gram nhé! Phải từng bước luyện chân kinh, không là tàu hỏa nhập ma ngay.
Chúng ta xét một mạng NN sau đây (thực ra đây là mạng NN cho Skip-gram đấy, nhưng tạm bỏ qua thông tin này nhé):

Giải thích cái mạng loằng ngoằng này trước đã:
- Bên trái là vector input của 1 từ (nhắc lại là của 1 từ nhé) được biểu diễn ở dạng one-hot, độ dài bằng số lượng từ vựng. Ví dụ số lượng từ là 10,000 thì vector này có độ dài 10,000 và chỉ có 1 giá trị 1 còn lại là 0. Cái tên One-hot là vì thế!
- Ở giữ là 1 hidden layer có độ dài bằng chính độ dài vector mà sau này chúng ta muốn dùng biểu diễn một từ.
- Output là layer có số unit = 10,000 luôn và giá trị output là probality xuất hiện các từ trong kho từ vựng vocabulary.
Để ý chút nữa là hàm activation chỉ xuất hiện ở layer cuối và là hàm softmax nhé còn hidden layer giữa không có.
Đấy, ta sẽ train cái mạng NN này và tính loss ngon lành, gradient descent hoành tráng để chỉnh weights tươm tất, đầy đủ!
Và cuối cùng, ta để ý cái hidden layer trung gian với size = 300 ở trên kia kìa, nó chính là vector sẽ được sử dụng để biểu diễn các từ sau khi huấn luyện mô hình đó! Kaka!
Bây giờ ta đi sâu hơn tý về 2 phương pháp CBOW và Skip-gram
Rồi, hiểu đại khái rồi thì bây giờ đến hiểu chi tiết cho nó đầy đủ. Tuy nhiên với tư tưởng Mì AI thì chi tiết ở đây cũng chỉ là hiểu dể dùng nhé, không toán, không chứng minh….
Giả sử số từ vựng bằng V, độ dài vector biểu diễn bằng N.
Phương pháp CBOW thì input là dùng dùng các vector one-hot của từ xung quanh để train và output là một vector có độ dài bằng V:
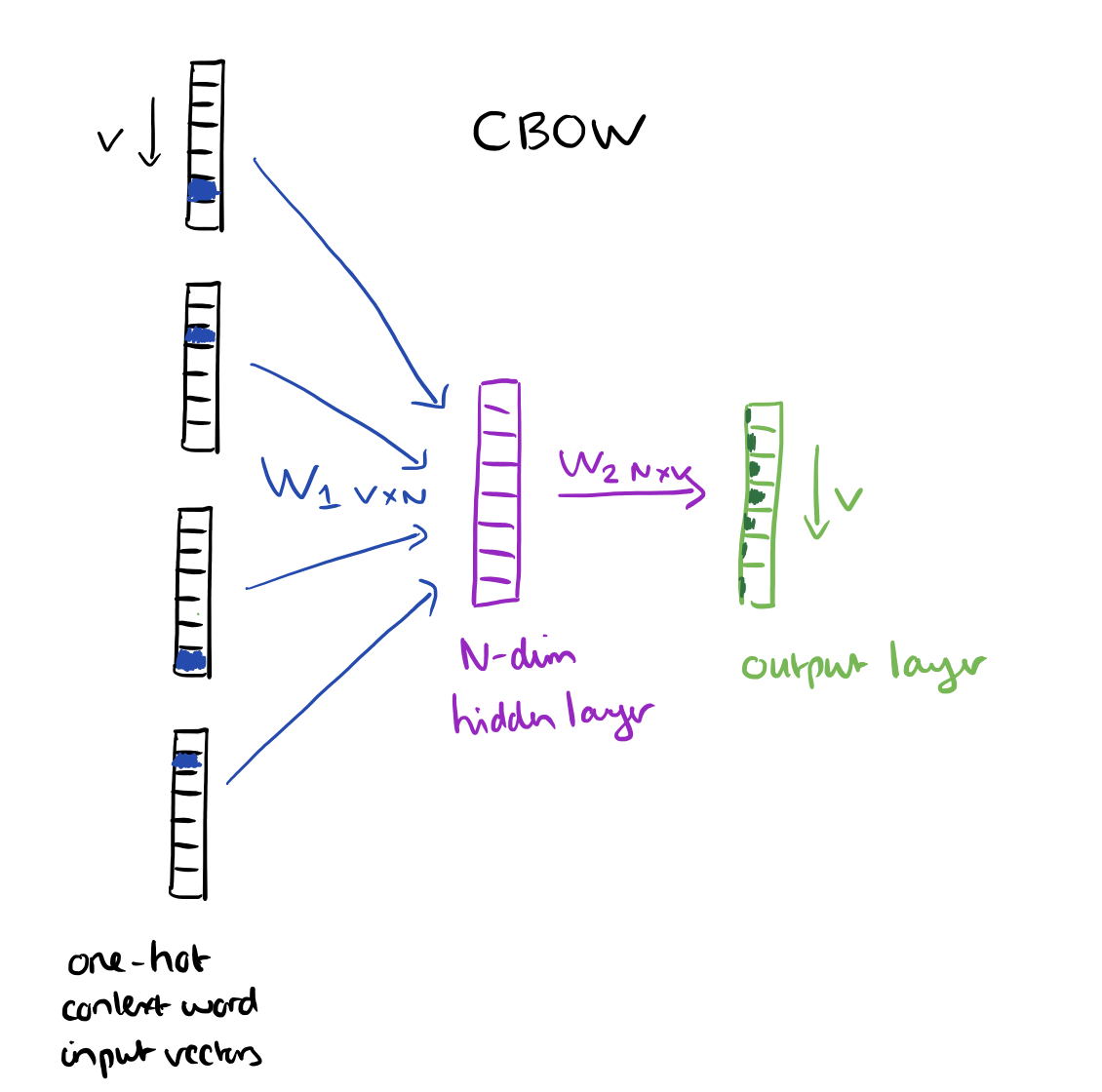
Train xong chán chê thì trích xuất cái vector màu tím ở giữa ra để làm vector đặc trưng cho từ output. Phương pháp này có điểm thuận lợi là training mô hình nhanh hơn so với mô hình skip-gram, thường cho kết quả tốt hơn với các từ ouput mà xuất hiện nhiều trong văn bản.
Phương pháp Skip-gram thì lại khác, ngược lại với CBOW, dùng 1 từ làm input để dự đoán các từ xung quanh. Skip-gram huấn luyện chậm hơn nhưng lại có ưu điểm là làm việc khá tốt với các tập data nhỏ và cho kết quả tốt cả với các từ ít xuất hiện trong văn bản (vì nó duyệt all từ input mà).
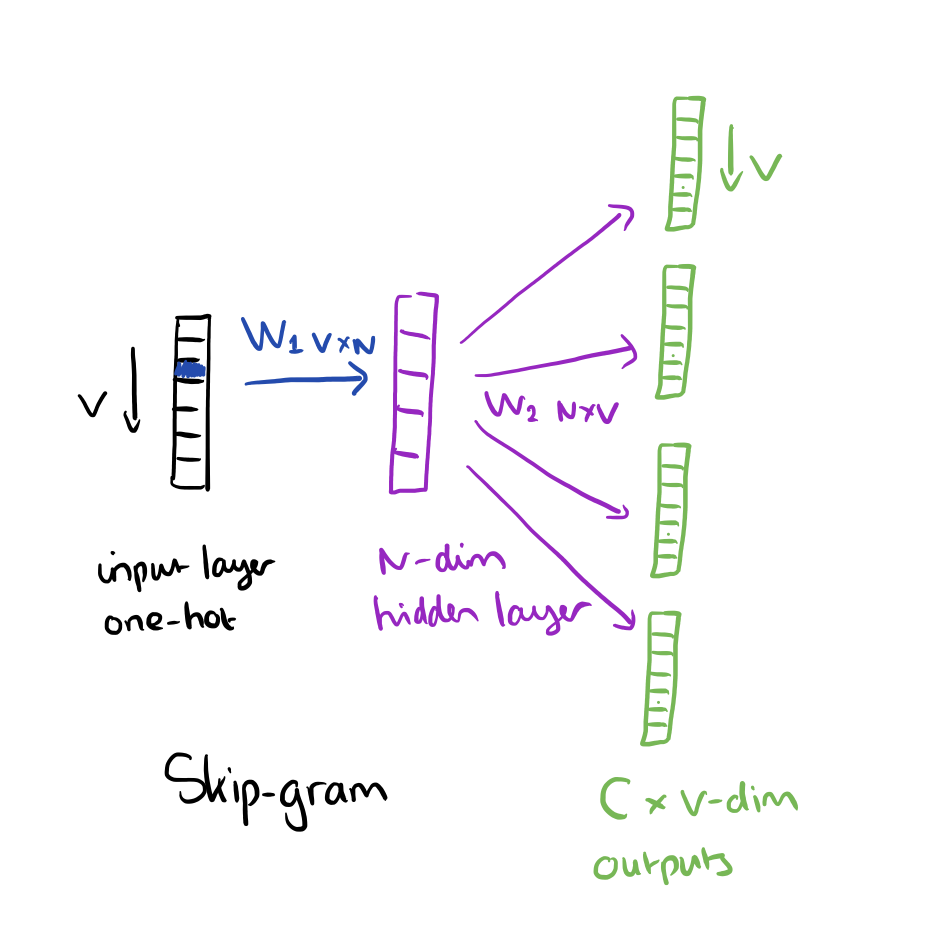
Và sau khi train xong thì cái màu tím ở giữa sẽ là vector đặc trưng cho từ input (ngược với ông CBOW).
Tóm váy phần 3: Well! Thế hết phần 3 ta có gì nhỉ? Ta đã hiểu rằng W2V train bằng mạng NN để tìm ra vector đặc trưng cho từ. Có 2 cách train là CBOW và Skip-gram và mỗi cái có ưu nhược riêng. Nhưng sau khi train xong đều lấy vector ở hidden layer làm vector đặc trưng cho từ. Done! Thế là đủ!
Phần 4 – Demo một số ưu điểm của Word2Vec
Chúng ta đã biết là mình cố tình dùng Word2Vec vì tính toán nhanh, thêm từ dễ rồi. Nhưng cái hay ho nhất của W2V là nó thể hiện được tương quan giữa các từ trong vocabulary. Thực ra món này cũng dễ hiểu vì ta train bằng mối quan hệ thì train xong cũng có mối quan hệ thôi.
Ví dụ 1: Các từ tương đồng sẽ có khoảng cách gần nhau như: Boston gần Seattle (cùng là địa danh ở bển), Had gần với Gave, talk gần với lecture và research gần với science…

Ví dụ 2: Từ ngữ cũng có thể nhân chia cộng trừ luôn mới ghê chứ. King sau khi bỏ đi yếu tố man và cộng yếu tố woman vào thì ra Queen. Nghĩa là ông vua có yếu tố hoàng gia, sau khi bỏ man đi và chuyển giới thì thành queen =)) (vẫn là hoàng gia).
Amazing đúng không các bạn?
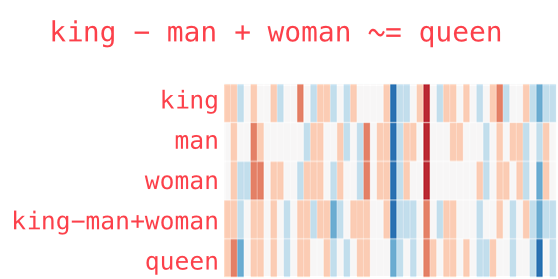
Và như vậy chúng ta đã có vector biểu diễn từng từ rồi nhỉ? Vậy với 1 câu văn bản thì sao? Thì ghép các vector biển diễn riêng lẻ đó vào nhau như cách chúng ta ghép vector onehot, vector đồng xuất hiện ở Phần 1 nhé các bạn!
Đến đây thì bài này đã quá dài rồi! Hi vọng phần nào giúp các bạn hiểu được nguyên lý hoạt động cơ bản của Word2Vec để biểu diễn từ. Trong bài tới mình sẽ thực hành luôn việc train và biểu diễn W2V trên Python nhé. Hẹn gặp lại các bạn!
Chào tạm biệt và chúc các bạn thành công!
Hãy join cùng cộng đồng Mì AI nhé!
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn/
Youtube: http://bit.ly/miaiyoutube