Xin chào các member Mì AI, hôm nay chúng ta cùng đi tiếp series “Oánh giá” model AI theo cách Mì ăn liền với một bài thực hành đánh giá model bằng Python.
Trong 2 bài trước trong series chúng ta đã làm quen với các khái niệm Loss, Accuracy, Precision, Recall, F1 Score. Bạn nào chưa đọc có thể đọc tại đây:
- “Oánh giá” model AI theo cách Mì ăn liền – Chương 1. Loss và Accuracy
- “Oánh giá” model AI theo cách Mì ăn liền – Chương 2. Precision, Recall và F Score
Sau khi mình đăng hai bài này thì các bạn có comment là khá dễ hiểu tuy nhiên vẫn yêu cầu có một bài thực hành cho thông hẳn luôn. Do đó hôm nay chúng ta cùng nhau thực hành một chút nha.
Okie, go go go!
Phần 1 – Lựa chọn bài toán
Do là để ví dụ cho các bạn hiểu nên chúng ta sẽ chọn một bài toán đơn giản thôi. Sau khi đã hiểu nguyên lý cách làm, các bạn có thể áp dụng với bài toán bất kì nhé!
Bài toán hôm nay chúng ta làm phải gọi là 1 bài toán kinh điển đó là phân loại hoa lan hay còn gọi là IRIS Classification. Bài toán nầy kinh điển đến lỗi Sklearn tích hợp luôn data để lúc cần dùng khỏi cần load từ bên ngoài. Haha!
Bài toán này chúng ta sẽ dựa vào thông tin bông hoa lan để dự đoán tên loài hoa lan. Ta có dữ liệu như sau:
- Input: Là 4 thông tin về các bông hoa lan gồm: chiều dài và rộng của cánh hoa, chiều dài và rộng của đài hoa. Ví dụ [5.84 3.05 3.76 1.2]
- Output: Là tên của loài hoa lan. Có 3 loài: 0 – Setosa, 1-Veriscolour và 2-Virginica

Bây giờ chúng ta cần train model sao cho khi đưa vào các thông số bông hoa thì model sẽ predict ra tên loài hoa.
Bài này là bài sample, có nhiều cách làm như SVM, KNN, …. nhưng hôm nay mình sẽ dùng hẳn Mạng nơ ron. Lý do? Đơn giản vì mình muốn demo cho các bạn cách oánh giá model là chính mà :D. Giải bài toán là phụ thôi.
Phần 2 – Triển khai bài toán
Load dữ liệu bài toán
Như mình đã nói, bài này không cần dùng dữ liệu ngoài. Các bạn load thẳng trong sklearn là okie:
# import thư viện
from sklearn.datasets import load_iris
# Thực hiện load dữ liệu
iris_data = load_iris()
# In ra 10 input đầu tiên
print('First 10 inputs: ')
print(iris_data.data[:10])
# In ra 10 output đầu tiên
print('First 10 output (label): ')
print(iris_data.target[:10])Code language: PHP (php)Và chúng ta sẽ có dữ liệu in ra như sau là chuẩn rồi:
First 10 inputs:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
First 10 output (label):
[0 0 0 0 0 0 0 0 0 0]Code language: CSS (css)Tiền xử lý dữ liệu và chia dữ liệu train, test
Dữ liệu đã load thành công, bây giờ ta cần chuẩn hóa một chút. Ở đây output đang có dạng là 0,1,2 và do đó ta cần đưa về OneHot cho tiện train model với hàm Softmax:
# Gán input vào biến X
X = iris_data.data
# Gán output vào biến y
y = iris_data.target.reshape(-1,1)
# Thực hiện Onehot transform
encoder = OneHotEncoder(sparse=False)
y = encoder.fit_transform(y)
print("Output after transform")
print(y)
# Chia dữ liệu train, test với tỷ lệ 80% cho train và 20% cho test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)Code language: PHP (php)Và đây, dữ liệu y – output đã được transform thành One hot vector:
Output after transform
[[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]
[1. 0. 0.]]Code language: CSS (css)Cài đặt mạng Nơ ron
Mọi thứ đã sẵn sàng bây giờ chúng ta sẽ cài đặt mạng NN thử nhé. Để đơn giản hóa mình sẽ dùng một mạng đơn giản với vài lớp thôi:
# Khai báo model
model = Sequential()
model.add(Dense(128, input_shape=(4,), activation='relu', name='layer1'))
model.add(Dense(128, activation='relu', name='layer2'))
model.add(Dense(3, activation='softmax', name='output'))
# Cài đặt hàm tối ưu Adam
optimizer = Adam()
model.compile(optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# In cấu trúc mạng ra màn hình
print('Detail of network: ')
print(model.summary())Code language: PHP (php)Và đây là kết quả trên màn hình
Detail of network:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
layer1 (Dense) (None, 128) 640
_________________________________________________________________
layer2 (Dense) (None, 128) 16512
_________________________________________________________________
output (Dense) (None, 3) 387
=================================================================
Total params: 17,539
Trainable params: 17,539
Non-trainable params: 0
_________________________________________________________________
NoneCode language: PHP (php)Để ý các bạn sẽ thấy mấy thông số hay ho:
- Cột Param# là số tham số của mỗi layer.
- Ở dưới cùng là có tổng số tham số cần train của model là 17,539.
- Hàm loss ở đây là categorical_crossentropy (đã nói ở bài Loss)
Train model và evaluate trên tập test
# Train model
model.fit(X_train, y_train, batch_size=32, epochs=10)
# Kiểm tra trên tập test
results = model.evaluate(X_test, y_test)
print('Test loss: {:4f}'.format(results[0]))
print('Test accuracy: {:4f}'.format(results[1]))Code language: PHP (php)Mình train với batch_size=32 và 10 epochs nhưng kết quả khá tốt với Test Loss là 0.263 và Test Accuracy là 0.9666
Epoch 1/10
120/120 [==============================] - 0s 159us/step - loss: 0.3818 - accuracy: 0.9833
Epoch 2/10
120/120 [==============================] - 0s 139us/step - loss: 0.3555 - accuracy: 0.9833
Epoch 3/10
120/120 [==============================] - 0s 133us/step - loss: 0.3323 - accuracy: 0.9583
Epoch 4/10
120/120 [==============================] - 0s 122us/step - loss: 0.3092 - accuracy: 0.9583
Epoch 5/10
120/120 [==============================] - 0s 124us/step - loss: 0.2900 - accuracy: 0.9750
Epoch 6/10
120/120 [==============================] - 0s 126us/step - loss: 0.2712 - accuracy: 0.9833
Epoch 7/10
120/120 [==============================] - 0s 120us/step - loss: 0.2543 - accuracy: 0.9750
Epoch 8/10
120/120 [==============================] - 0s 119us/step - loss: 0.2424 - accuracy: 0.9833
Epoch 9/10
120/120 [==============================] - 0s 129us/step - loss: 0.2289 - accuracy: 0.9667
Epoch 10/10
120/120 [==============================] - 0s 117us/step - loss: 0.2065 - accuracy: 0.9833
30/30 [==============================] - 0s 1ms/step
Test loss: 0.263040
Test accuracy: 0.966667Như vậy là bài toán của chúng ta đã xong về mặt triển khai. Nhưng như vậy thì cụt quá nhở. Chúng ta hãy thêm thắt tý cho nó phong phú đa dạng nhở. Đi tiếp nhé!
Phần 3 – Đánh giá model qua Graph và các thông số Precision , Recall và F Score
Vẽ đồ thị loss và accuracy
Bây giờ việc đầu tiên là ta sẽ in ra đồ thị Loss và Accuracy nhé. Để làm việc đó mình tăng số epoch lên 200 cho đồ thị nó đẹp:
# Train model
import matplotlib.pyplot as pyplot
history = model.fit(X_train, y_train, batch_size=32, epochs=200,validation_data=(X_test,y_test))
# plot loss và accuracy
pyplot.figure(figsize=(20,10))
pyplot.subplot(211)
pyplot.title('Loss')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend()
# plot accuracy during training
pyplot.subplot(212)
pyplot.title('Accuracy')
pyplot.plot(history.history['accuracy'], label='train')
pyplot.plot(history.history['val_accuracy'], label='test')
pyplot.legend()
pyplot.show()Code language: PHP (php)Và đây là đồ thị này! Nhìn có vẻ chuyển nghiệp vê lờ anh em nhở =)). Chúng ta ko bàn về độ chính xác của model nhé, thực hành cách đánh giá thôi 🙂

Tính toán Confusion Matirix, Precision, Recall và F1-Score
Rồi như vậy là loss và acc đã xong, bây giờ tính mấy cái món này cho nó có vẻ pờ rồ nào.
Mình nói có vẻ pro vì thư viện sklearn đã hỗ trợ khá tốt rồi, anh em chỉ cần gọi ra cho đúng là okie. Anh em nào cần tìm hiểu chi tiết các hàm thì có đây luôn: tại đây.
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import confusion_matrixCode language: JavaScript (javascript)Đó, thư viện tận răng và bây giờ là gọi :
y_hat = model.predict(X_test)
y_pred = np.argmax(y_hat, axis=1)
y_test_label = np.argmax(y_test, axis=1)
# Tính accuracy: (tp + tn) / (p + n)
accuracy = accuracy_score(y_test_label, y_pred)
print('Accuracy: %f' % accuracy)
# Tính precision tp / (tp + fp)
precision = precision_score(y_test_label, y_pred, average='macro')
print('Precision: %f' % precision)
# Tính recall: tp / (tp + fn)
recall = recall_score(y_test_label, y_pred, average='macro')
print('Recall: %f' % recall)
# Tính f1: 2 tp / (2 tp + fp + fn)
f1 = f1_score(y_test_label, y_pred, average='macro')
print('F1 score: %f' % f1)
# Tính Area under ROC
auc = roc_auc_score(y_test, y_hat, multi_class='ovr')
print('ROC AUC: %f' % auc)
# Tính confusion matrix
matrix = confusion_matrix(y_test_label, y_pred)
print(matrix)Code language: PHP (php)Đoạn source trên anh em chú ý mấy điểm sau:
- Hàm tính Acc, Precision, Recall và F1 mình dùng phương pháp trung bình macro nhé. Nếu anh em ko có tham số này nó sẽ phun ra cả 1 mảng với mỗi phần tử là giá trị cho 1 class. (one -vs-rest vì bài toán là multi classs)
- Hàm roc_auc_score mình cũng thêm multi_class = ‘ovr’ là One-vs-rest để nó hiểu.
Và kết quả ngon lành cho anh em:
Accuracy: 0.933333
Precision: 0.944444
Recall: 0.939394
F1 score: 0.936364
ROC AUC: 0.993477
[[ 9 0 0]
[ 0 9 2]
[ 0 0 10]]Code language: CSS (css)Đến bước này anh em lại thấy rằng cái Confusion matrix có vẻ chưa clear lắm, nhìn như này thì ai biết phán như nào. Okie! Ta lại vẽ nó ra cho trực quan:
import pandas as pd
import seaborn as sn
df_cm = pd.DataFrame(matrix, index = [i for i in "012"],
columns = [i for i in "012"])
pyplot.figure(figsize = (10,7))
sn.heatmap(df_cm, annot=True)Code language: JavaScript (javascript)Ở đây ta dùng thư viện pandas và searborn để vẽ đồ thị Heatmap và kết quả đây rồi:
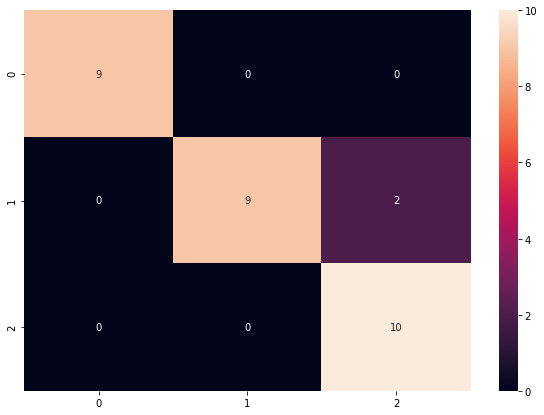
Rồi bây giờ thì rõ như ban ngày và phán thôi nhỉ?
- Có tất cả 9 mẫu số 0 và được predict đúng hết vào class 0. Ngon!
- Có tất cả 11 mẫu số 1 và được predict đúng 9 mẫu vào class 1 và 2 mẫu bị sai (predict vào class 2)
- Tương tự, có 10 mẫu số 2 và predict đúng cả 😀
Kết luận, model ngon lành kaka!
Và do bạn đã kiên nhẫn đọc đến cuối bài nên quà tặng mình dành cho bạn là source mình đã code sẵn tại đây. Các bạn có thể tải về và thử luôn nhé.
Okie, vậy là mình đã guide các bạn cách triển khai đánh giá model phân loại classify theo các món Loss, Acc, Pre, Recall, Confusion Matrix….
Mình xin dừng bài này lại đây. Hẹn gặp lại các bạn trong các bài tiếp theo nhé!
Hãy join cùng cộng đồng Mì AI nhé!
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn
Youtube: http://bit.ly/miaiyoutube
Em có thể đánh giá độ chính xác của một mô hình học máy có sẵn trong thư viện của python dựa trên bộ mẫu của riêng em được không ạ?
Em đang muốn đánh giá độ chính xác của thư viện face-recognition trong thư viện python ạ. Em cám ơn
Em post lên Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup trao đổi cho tiện nha!