Chào toàn thể anh em Mì, hôm nay mình xin chia sẻ chút kiến thức nhỏ nhoi của mình về Object Detection nhé.
Thời gian nhanh vãi cả lúa, thấm thoắt mà lại cuối tuần rồi. Hôm nay lại là Thứ 6 rồi. Tranh thủ đang ngồi trên Airport chờ take off nên note vài dòng chia sẻ.
Chắc hẳn anh em đã quá quen thuộc với các thuật ngữ Object Detecion (OD) hay là nhận diện đối tượng trong ảnh. Cái này nó khác với Image Classification (IC) nhé.
- IC là đưa một tấm ảnh và đầu ra là kết quả tấm ảnh đó là cái gì. Ví dụ: chó, mèo, lợn, gà hay gái, trai…
- OD thì khác, input sẽ là một tấm ảnh và đầu ra sẽ là các vật thể, đối tượng có trong ảnh đó kèm theo toạ độ (bounding box) của nó. Ví dụ: có chó tại tạo độ x1,y1,x2,y2 và có mèo tại toạ độ x3,y3,x4,y4…
Chính do sự khác nhau như vậy nên cấu trúc mạng cho các bài toán IC và OD cũng khác nhau. Với bài toán IC thì đơn thuần là sử dụng một mạng CNN thông thường với input và output cố định (input là size ảnh (W,H,D) và output là Dense(1) hoặc Dense(n_class)…).

Với bài toán OD thì khó hơn vì rõ ràng là output không cố định. Tuỳ vào số lượng đối tượng có trong ảnh mà số output sẽ khác nhau. Có ảnh thì chả có gì, có ảnh thì vài con chó, có ảnh lại cả mớ con mèo kaka.
Do vậy, dã có nhiều tác giả đề xuất các phương án rất hay và đẹp để xử lý các bài toán OD trong nhiều năm qua. Chúng ta hãy cùng điểm qua vài “bí kíp võ công” nổi tiếng nhé.
Phần 1 – Khởi đầu cho Object Detection
Để tìm giải pháp cho OD trên một bức ảnh thì suy nghĩ rất tự nhiên là ta sẽ sử dụng một cái kéo và một mạng CNN. Cách thực hiện vô cùng đơn giản là cắt riêng các vùng ảnh sau đó đưa từng vùng ảnh đó vào mạng CNN để xem trong vùng đó có cái giống gì. Nếu phát hiện vật thể trong vùng ảnh nào đó thì lưu lại vị trí đã cắt để làm bounding box kaka.
Các làm đơn giản này gặp khá nhiều khó khăn bởi các vật thể có kích thước khác nhau giữa các ảnh, góc quay, hướng quay khác nhau giữa các ảnh nên số lượng vùng ảnh phải rất lớn và “cực phong phú đa dạng” về kích thước, tỷ lệ thì may ra mới phát hiện được hết các vật thể trong ảnh.
Điều này làm cho thuật toán chạy chậm và tốn nhiều tài nguyên tính toán.
Phần 2 – R-CNN
Đến năm 22/10/2014 (đúng ngày sinh nhật mình mới ghê 😀 ) , các đại ca Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik mới nghĩ ra cách cải tiến cái món khởi đầu ngô nghê kia.
Cách làm là thay vì chọn cả mớ vùng ảnh sau đó vù ng nào cũng áp CNN vào rồi chậm như con rùa, hỏng cả máy tính thì các đại ca áp dụng một thuật toán Selective Search để chọn ra 2000 vùng ảnh từ những vùng ảnh được sinh ra ban đầu. Sau đó mới áp dụng CNN vào 2000 vùng ảnh đó. Bớt đi được ối việc cho máy tính đó.

Chi tiết hơn về cái việc áp CNN vào các vùng ảnh một chút thì các bạn để ý hình trên sẽ thấy:
- Input: là vùng ảnh được trích ra trên ảnh gốc.
- Output: Thông qua trích đặc trưng và predict sẽ cho ra được class của vùng ảnh cũng như 4 giá trị offset để điều chỉnh bounding box quanh vật thể trong vùng ảnh.Ví dụ có một vùng ảnh nhận là chó, nhưng không phải cả vùng ảnh đó là con chó mà chỉ có nửa người con chó thôi thì bounding box không thể là cả vùng ảnh đó được, ta dùng offset để chỉnh cho bounding box vào đúng phần thân con chó.
Step by step các bạn có thể nhìn trong ảnh dưới, khá rõ ràng luôn.

Đến đây chắc các bạn đã thấy object detection bằng R-CNN ngon vê lờ rồi đúng không, nhưng chưa đâu! Các anh Tây lông chỉ ra nó còn nhiều nhược điểm cần cải tiến như:
- Số lượng vùng ảnh vẫn lớn và vẫn chọn một cách ngẫu nhiên, thủ công mỹ nghệ và do đó nhiều vùng ảnh chả có cái gì cũng mất công đưa vào CNN để predict.
- Do các điểm trên nên tốc độ predict khá chậm, tốn đến 47s/ ảnh (vào thởi điểm tác giả thử nghiệm).
Và thế là, món mới lại được các anh Tây lông nấu ra!
Phần 3 – Fast R-CNN
Vâng, tác giả của món object detection R-CNN đã tự nâng cấp thành Fast R-CNN trong một nghiên cứu tiếp theo với mong muốn tăng tốc độ predict bằng cách giảm chi phí tính toán cho máy tính.
Cơ bản về cách làm cũng same same với R-CNN nhưng cải tiến quan trọng nhất giúp tăng tốc độ tính toán là thay vì input 2000 vùng ảnh trực tiếp vào trong mạng CNN thì các đại ca đã thực hiện đưa cả ảnh vào mạng CNN 1 lần duy nhất.
Sau khi đưa vào CNN thì ta sẽ có Feature Map với kích thước nhỏ hơn ảnh gốc rất nhiều. Và bây giờ ta sử dụng một ROI Pooling layer để đưa các vùng ảnh về kích thước vuông và reshape về cùng một kích thước đầu ra. Với kết quả có được, ta lại đưa tiếp qua các lớp FCs và có được một output gọi là ROI feature vector.
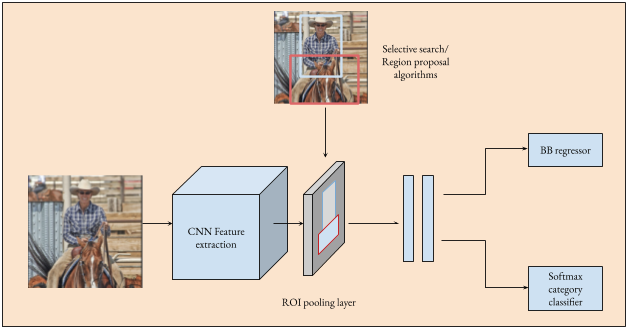
Rồi, có được ROI feature vector rồi thì đơn giản rồi, ta lại predict class và offset của bounding box cho vùng mảnh đó để lấy kết quả đầu ra như đã làm với R-CNN.
Như vậy, nhìn lại một chút thì Fast R-CNN nhanh hơn R-CNN ở chỗ thay vì mất 2000 lần đưa các vùng ảnh vào CNN thì chỉ cần 1 lần đưa ảnh gốc vào CNN. Tuy nhiên, việc lựa chọn các vùng ảnh bằng seletive search trên Feature Maps vẫn là nút thắt và làm chậm cho thuật toán.
Phần 4 – Faster R-CNN
Vâng, và một lần nữa thuật toán Object Detection mới lại ra đời để xử lý cái nút thắt nói trên. Nhưng lần này không phải là các đại ca cũ nữa mà là đại ca Shaoqing Ren với thuật toán Faster R-CNN.
Về cơ bản thuật toán này tập trung xử lý cái nút thắt – Selective Search để tăng tốc. Họ đã cải tiến bằng cách thay vì thủ công mỹ nghệ lựa chọn thì build luôn một mạng cho nó học luôn đâu là vùng ảnh nên chọn để tìm kiếm object. Quá đỉnh!
Thế cụ thể họ làm thế nào? Họ cũng áp dụng giống Fast R-CNN đó là đưa ảnh vào CNN để lấy feature map (FM) cái đó. Cứ phải cho nó nhỏ đi rồi tính tiếp chứ to tướng như ảnh gốc thì tính toán chết mất. Nhưng cái khác là sau khi có FM thì thay vì dùng selective search thì đưa cái FM vào một cái mạng riêng gọi là Regional Proposal Network (RPN) – mạng tìm kiếm các vùng ảnh. Thế là sau khi qua cái mạng đó thì ta có các vùng ảnh có khả năng chứa object rồi. Quá okie thay vì tìm hú hoạ.
Cuối cùng thì đơn giản hơn đan rổ, ta đưa các vùng ảnh tìm được qua ROI Pooling layer để reshape, rồi sau đó sử dụng một số lớp FCs tiếp theo để predict class, offset của bounding box như các thuật toán trên.
Nhanh hơn ở đây là khử cái thằng selective search và thay vì phải predict trên các vùng ảnh hú hoạ thì ta chỉ cần xử lý trên các vùng ảnh có khả năng chứa vật cao nhất mà thôi.
Các bạn có thể xem bảng so sánh dưới đây để thấy rằng tốc độ thử nghiệm của Faster R-CNN đã khá ổn và có thể áp dụng vào các bài toán thời gian thực.

Tuy nhiên, trùm cuối vẫn chưa xuất hiện ở màn này đâu, các bạn hãy đọc tiếp để gặp nhé kaka
Phần 5 – YOLO, thánh Object Detection
Đây phải nói là cái tên quá nổi tiếng rồi. Version mới nhất của ông YOLO này là phiên bản số 4 (bản số 5 còn nhiều tranh cãi và chưa có paper chính thức nên mình chưa đưa vào bài).
Như vậy đến phần Faster R-CNN chúng ta đã đạt được thành quả khá ổn với việc chỉ xử lý trên các vùng ảnh có khả năng chứa object cao nhất thay vì xử lý toàn ảnh như lúc ban đầu. Tuy nhiên, YOLO còn làm hơn thế nữa 😀
YOLO là You Only Look Once và đúng như vậy, nó không xem xét từng vùng mà nhìn toàn bộ bức ảnh một lần sau đó predict ra class, bounding box cho từng object trong hình. Ghê vê lờ luôn!
Chắc các bạn đang tò mò xem nó làm như nào mà gớm vậy. Chúng ta cùng đi tiếp nhé.
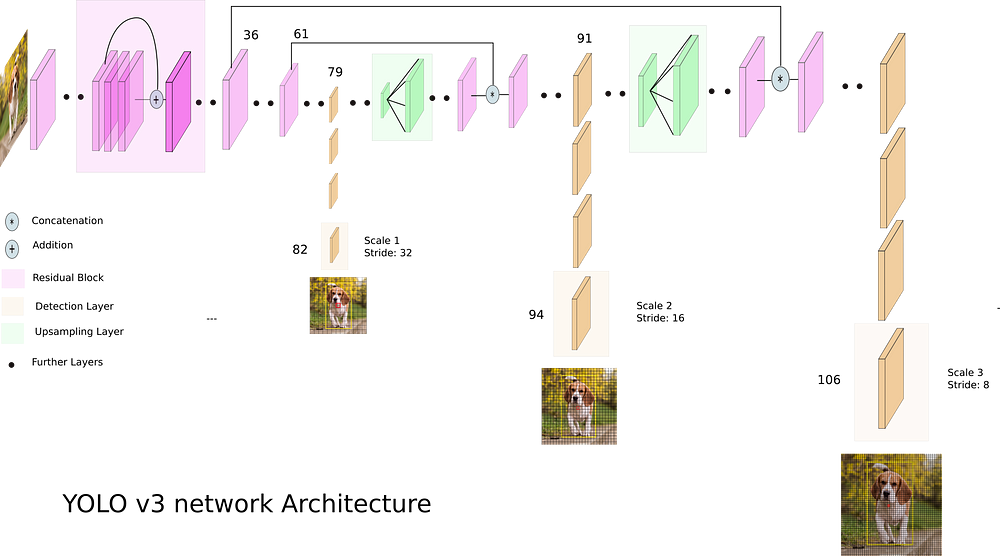
Thay vì xét vùng này vùng kia thì ông YOLO chia ảnh thành một lưới vuông với kích thước giả sử là NxN chẳng hạn. Sau đó nó duyệt từng ô trong ảnh, với mỗi ô thì lại thử m cái anchor box. Với mỗi anchor box đó thì sẽ dự đoán class và offset của bounding box của vật thể. Cuối cùng thì các bouding box có xác suất lớn nhất trên ngưỡng sẽ được giữ lại áp dụng một thuật toán có tên Non Max Supression (NMS) để chỉ giữ lại các bounding box tốt nhất và output ra kết quả cho người dùng.
Xét về tốc độ thì YOLO hiện đang khá nhanh so với các phương pháp nói trên (tốc độ thử nghiệm max đạt được là 45 FPS). Tuy vậy điểm yếu của YOLO lại là hay bỏ sót các object nhỏ trên ảnh như: phát hiện xe trên ảnh vệ tinh, ảnh chụp flycam….
Trong thực tế mạng YOLOv3 đã sử dụng 3 lưới khác nhau (3 feature map size khác nhau) để tiến hành predict trên các ô của lưới. Điều này làm tăng khả năng detection của mạng, tránh bỏ sót.
Ok, trên đây là toàn bộ những gì mình đã học và đã biệt về món Object Detection, mình muốn chia sẻ cùng các bạn đang tìm hiểu để cùng học hỏi, rút ngắn thời giam tìm hiểu. Hi vọng món Object Detection càng ngày càng phát triển mạnh nữa để anh em có nhiều công cụ thực hành.
Ps: Về YOLO trên Mì Ai đã có khá nhiều bài, các bạn có thể tham khảo qua link này Blog: https://miai.vn/?s=yolo
Chúc các bạn thành công!
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: http://miai.vn
Youtube: http://bit.ly/miaiyoutube
Cảm ơn các bài viết tham khảo tuyệt vời:
-
-
-
-
-
-
-
-
Show Commentsdạ anh ơi , anh có thể nói 1 cách tổng quan về mô hình ssd-mobilenet được không ạ , em cảm ơn anh !
bài viết quá hay ạ!
Thanks bạn ủng hộ nhé.
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup
Blog: https://miai.vn
Youtube: http://bit.ly/miai_youtube
Anh ơi
Anh có thể demo Object Detection với Faster R-CNN được ko ạ
Okie em. Bài tiếp theo nhé!
Anh ơi, em cũng đang làm 1 đồ án nhận dạng bằng Faster R-CNN
Em là newbie nên đang ko biết làm như nào, mong a có thể làm demo hướng dẫn về cái này ạ
Em cảm ơn ạ
Em cứ post bài toán cụ thể lên Group trao đổi, chia sẻ: https://facebook.com/groups/miaigroup rồi cùng trao đổi nhé!
[…] Cách thực hiện vô cùng đơn giản là cắt riêng các vùng ảnh sau đó đưa từng vùng ảnh đó vào mạng CNN để xem trong vùng đó có cái giống gì. Nếu … Xem Thêm […]