Chào các anh em, hôm nay chúng ta sẽ cùng tìm hiểu về thư viện Hugging Face – một món đồ bá đạo giúp chúng ta làm các task NLP vô cùng đơn giản và dễ dàng.
Hugging Face với slogan của nó là ” On a mission to solve NLP,
one commit at a time” và địa chỉ trang chính của nó là https://huggingface.co. Anh em có thể tham khảo thêm tại trang này nhé.
Còn bây giờ, let’s go!
Chú ý là phần này nếu bạn nào chưa hiểu rõ có thể hỏi thêm trên Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup nhé. Các bạn nên clear phần này để có thể theo các bài tiếp theo nha!
Phần 1 – Các “dị bản” của BERT
Ngay sau khi BERT ra mắt và tạo nên tiếng vang lớn trong làng NLP, một loạt các phiên bản cải tiến, biến thể, dị bản như RoBERTa, ALBERT, DistilBERT,… được cho ra mắt với các cải tiến khác nhau về: độ sâu, số lớp, số head, các ngôn ngữ khác nhau.
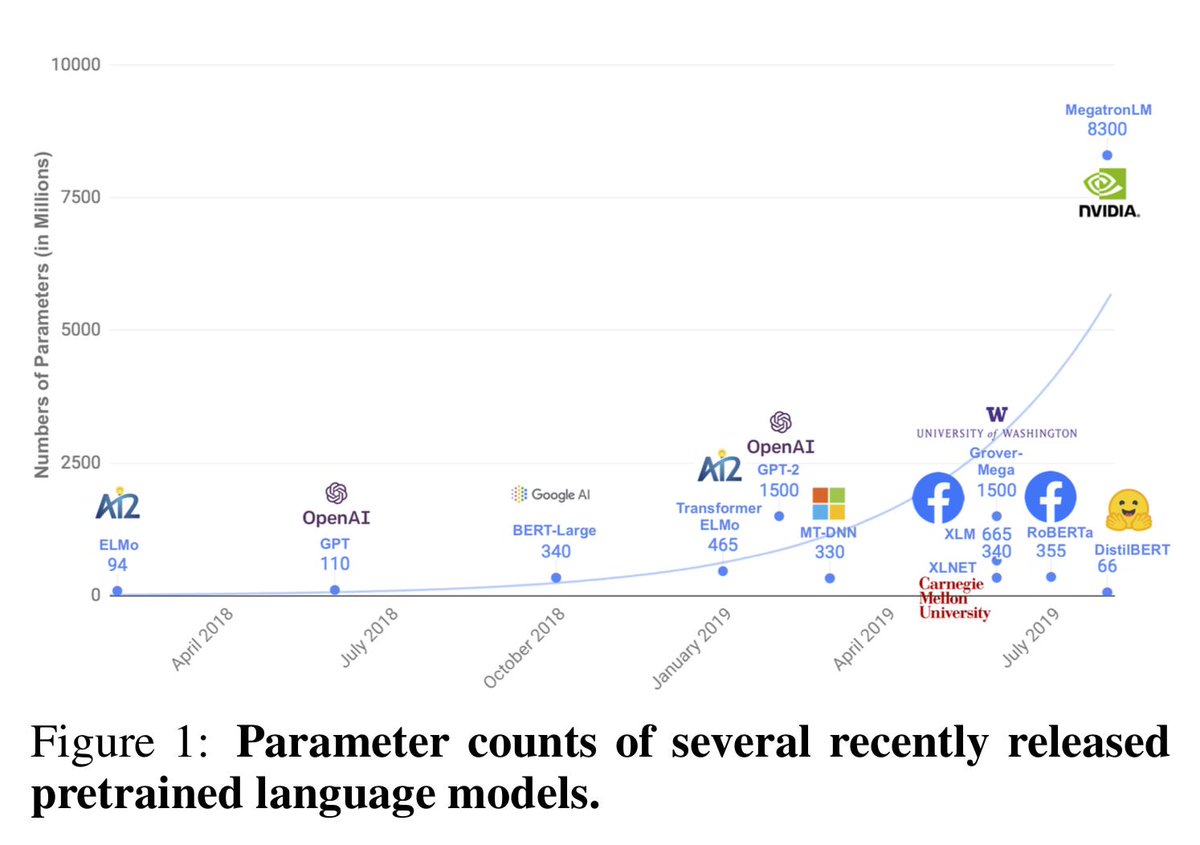
Chúng ta cũng không cần tìm hiểu hết các phiên bản BERT trên làm gì cho mệt, cần cái nào ta học cái đó thôi. Đa phần với người Việt chúng ta thì sẽ cần 2 món là BERT cho tiếng Anh và BERT cho tiếng Việt (PhoBERT) , thế là đủ!
Cái nay nhất ở đây chính là nó là pretrain nhé! Nghĩa là họ train rồi, ta chỉ sử dụng thôi (còn nếu thích thì finetune tý ).
Đến đây các bạn sẽ thắc mắc là nhiều phiên bản thế, nhiều món thế thì ăn làm sao? Dùng thế nào? Và rất may là đã có thư viện siêu dễ dùng có tên Transformers của Hugging Face. (trong bài sau sẽ có món https://simpletransformers.ai )
Phần 2 – Thử cài đặt và trích xuất đặc trưng văn bản bằng Hugging Face (HF)
Ok như vậy qua phần bên trên các bạn chỉ cần nhớ là “Có nhiều phiên bản BERT vãi lúa nhưng ta không sợ vì có bạn Hugging Face dễ thương”.

Bây giờ chúng ta sẽ cùng thử nghịch HF một chút nào . Chú ý là đã sờ đến BERT thì các bạn nên chuẩn bị máy tính có cấu hình khá khá một chút nhé, nếu không thì sẽ chạy ì ạch lắm đấy.
Trong bài này mình chưa nói gì đến các task cụ thể phía sau (Downstream task) như : Sentiment Classificaiton, Q&A… Mình chỉ guide các bạn cách cài đặt, tokenizer, và trích xuất đặc trưng của câu văn bản bằng BERT qua thư viện Hugging Face.
Cài đặt thư viện
Để sử dụng được Hugging Face các bạn cài đặt bằng 2 lệnh:
# Cài đặt thư viện transformers của Huggging Face
pip install transformers
# Cài đặt pytorch do thằng HF toàn dùng pytorch :D
pip install torchKhai báo các thư viện
import transformers
import torch
from transformers import BertModel, BertTokenizerLoad các pretrain model
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
Trong hai dòng bên trên:
- Dòng đầu tiên ta load model từ BERT pretrain. Cụ thể ở đây là model bert-base (bản nhỏ) và uncased (không care viết hoa, thường)
- Dòng thứ hai ta load cái Tokenizer. Sử dụng để tokenize các từ trong câu.
Chú ý ở bước này trong lần chạy đầu tiên sẽ rất chậm nhé. Lý do bởi vì hugging face nó sẽ tải các pretrain model từ internet về, cái nào cũng toàn mấy trăm MB nên không lâu mới là lạ 😀

Tokenizer câu văn bản
Như chúng ta đã biết, máy tính nó chỉ hiểu số number mà thôi, nó không hiểu văn bản, nên chúng ta phải chuyển từ câu văn sang một “mảng” các chữ số, đó chính là tokenizer.
Để làm việc đó, chúng ta dùng đoạn lệnh sau:
sent = "I want to learn Python"
print("Câu văn = ", sent)
token = tokenizer.encode(sent)
print("Token array = ", token)
Nếu các bạn để ý thì hình như token đang dài hơn Câu văn (7 item so với độ dài 5 từ của câu văn). Đúng đó, Bert đã tự thêm vào 2 token đặc biệt là [CLS] ở đầu câu và [SEP] ở cuối câu. Lý do vì sao lại thế thì các bạn xem lại bài trước của mình tại đây nhé.
Chúng ta thử dịch ngược lại xem có đúng ko nhé:
d_sent = tokenizer.decode(token)
print("Decode sentence = ", d_sent)Và kết quả chuẩn luôn, đúng là đã bị thêm 2 món kia vào :

Trích xuất đặc trưng câu văn
Okie, vậy là chúng ta đã token, số hóa được câu văn rồi. Giờ chúng ta sẽ đưa câu văn vào BERT để trích ra đặc trưng nhé:
# Chuyển token array thành tensor
sent_tensor = torch.tensor([token])
print(sent_tensor.size())
# Xây dựng attention_mask, ở đây là mảng toàn 1 vì ta quan tâm đến all các token
attention_mask = torch.tensor([np.ones(7)])
print(attention_mask.size())
# Trích đặc trưng
with torch.no_grad():
last_hidden_states = model(input_ids = sent_tensor, attention_mask = attention_mask)
# In kích thước và giá trị đặc trưng ra màn hình
print(last_hidden_states[0].size())
print(last_hidden_states[0])
Chỗ này có mấy điểm các bạn cần lưu ý:
- Thứ nhất, trong pytorch ra dùng lệnh .size() để in ra kích thước tensor.
- Thứ hai, attention mask là gì? Đó là một ma trận/vector có kích thước bằng với vector token và có giá trị là 0/1 để chỉ ra các token nào Bert cần quan tâm và token nào không cần quan tâm. Trong trường hợp này, chúng ta quan tâm all các token nên để là 1 hết. Khi chúng ta xử lý nhiều câu văn bản có độ dài khác nhau, ta sẽ padding thêm các giá trị đặc biệt, và khi đó ta bảo model là : hãy đừng quan tâm đến các cái tao padding thêm vào bằng cách set các giá trị tương ứng trong attetion mask = 0 😀
- Thứ ba, output embedding mà chúng ta mong muốn sẽ có size là (1,7,768) . Điều này có nghĩa là có tất cả 7 embedding vector cho 7 từ trong câu (bao gồm cả 2 cái từ đặc biệt [CLS] và [SEP] đó) và mỗi vector có độ dài 768.
Rồi, bây giờ chúng ta đã trích được đặc trưng cho câu văn bản bằng BERT. Trong các bài tiếp theo, chúng ta sẽ dùng toàn bộ output embedding hoặc chỉ dùng vector embedding tại vị trí token [CLS] (vị trí 0) để xử lý tiếp.
Phần này nếu bạn nào chưa hiểu rõ có thể hỏi thêm trên Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup nhé. Các bạn nên clear phần này để có thể theo các bài tiếp theo nha!
Hẹn các bạn trong các bài tiếp theo nha!
Chúc các bạn thành công!
#MìAI
Fanpage: http://facebook.com/miaiblog
Group trao đổi, chia sẻ: https://www.facebook.com/groups/miaigroup
Website: https://miai.vn/
Youtube: http://bit.ly/miaiyoutube
hóng phần tới, thank a.
Thanks em. ANh sẽ cố ra nhanh nhất có thể!
[…] Trong 2 bài trước, mình đã cùng các bạn tìm hiểu về BERT. Bạn nào chưa xem thì có thể xem lại tại đây [BERT Series] Chương 1. BERT là cái chi chi? và [BERT Series] Chương 2. Nghịch một chút với Hugging Face […]